Feature, Not a Bug
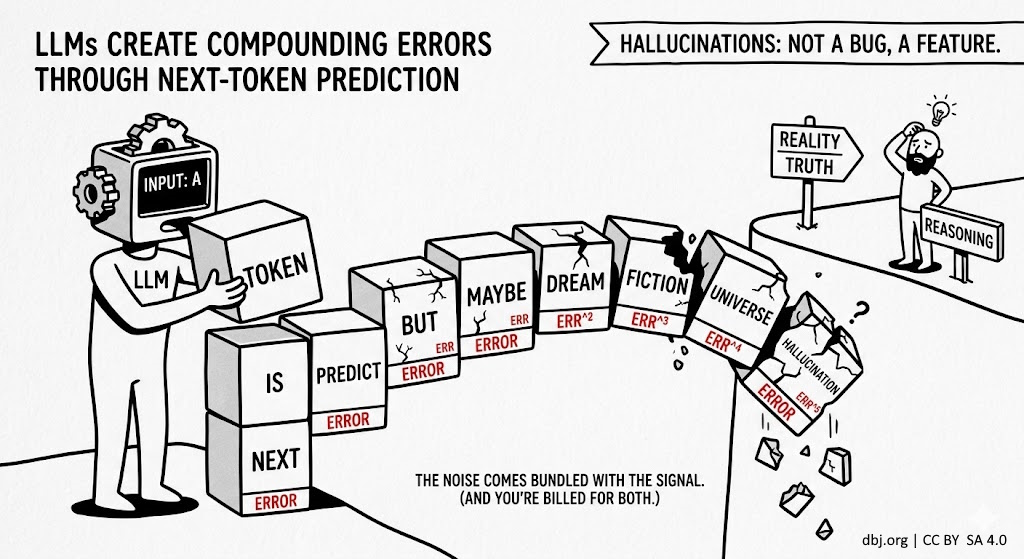
© Dusan B. Jovanovic — image generated with Gemini under author’s direction Nobody told you this when you readily signed up for the API key. Every LLM has the same training objective: predict the next token. Not the next true thing. Not the next logical step. The next token — one symbol, conditioned on all the symbols before it. That’s it. That’s the whole game. IMPORTANT It produces text that reads beautifully. It reasons the way a drunk navigates by streetlights — confident, directional, and increasingly wrong. Here is the mechanical problem. Each generated token feeds back into the context as input for the next prediction. So when the model makes a small error at step one, that error is now part of the premises at step two. The mistake doesn’t stay put. It becomes ground truth. The next token is predicted on top of a lie, and the one after that on top of a slightly larger lie, and so on down the chain until you’ve arrived somewhere that sounds perfectly coherent and has nothing to do with reality. ...